
For a professional C++ developer, it’s important to understand memory organization of the data
structures, especially when it comes to the containers from the C++ Standard Library. In this post
of Tasty C++ series we’ll look inside of std::string, so that you can more effectively work with
C++ strings and take advantage and avoid pitfalls of the C++ Standard Library you are using.
In C++ Standard Library, std::string is one of the three
contiguous containers (together
with std::array and std::vector). This means that a sequence of characters is stored in a
contiguous area of the memory and an individual character can be efficiently accessed by its index
at O(1) time. The C++ Standard imposes more requirements on the complexity of string operations,
which we will briefly focus on later in this post.
If we are talking about the C++ Standard, it’s important to remember that it doesn’t impose exact
implementation of std::string, nor does it specify the exact size of std::string. In practice,
as we’ll see, the most popular implementations of the C++ Standard Library allocate 24 or 32 bytes
for the same std::string object (excluding the data buffer). On top of that, the memory layout of
string objects is also different, which is a result of a tradeoff between optimal memory and CPU
utilization, as we’ll also see below.
Long Strings
For people just starting to work with strings in C++, std::string is usually associated with three
data fields:
- Buffer – the buffer where string characters are stored, allocated on the heap.
- Size – the current number of characters in the string.
- Capacity – the max number of character the buffer can fit, a size of the buffer.
Talking C++ language, this picture could be expressed as the following class:
1class TastyString {
2 char * m_buffer; // string characters
3 size_t m_size; // number of characters
4 size_t m_capacity; // m_buffer size
5}
This representation takes 24 bytes and is very close to the production code.
Let’s see how this compares to the actual size of std::string. This is given by
sizeof(std::string) and in the most popular implementations of the C++ Standard Library is the
following:
| C++ Standard Library | Size of std::string() |
|---|---|
| MSVC STL | 32 bytes |
| GCC libstdc++ | 32 bytes |
| LLVM libc++ | 24 bytes |
What a surprise, only LLVM allocates expected 24 bytes for std::string. The other two,
MSVC and GCC, allocate 32 bytes for the same string. (Numbers in the table are for -O3
optimization. Note that MSVC allocates 40 bytes for std::string in the debug mode.)
Let’s get some intuition about why various implementation allocate different amount of memory for the same object.
Small Strings
You have already noticed that the fields of TastyString and std::string contain only the
auxiliary data, while the actual data (characters) is stored in the buffer allocated on the
heap. However, when the actual data is small enough, it seems inefficient to reserve 24 or 32 bytes
for the auxiliary data, isn’t it?
Small String Optimization. This is what the small string optimization (aka SSO) is used for.
The idea is to store the actual data in the auxiliary region with no need to allocate the buffer on
the heap, that makes std::string cheap to copy and construct (as it’s only 3x-4x times more than
fundamental types such as void *, size_t, or double). This technique is popular among various
implementations, but is not a part of the C++ Standard.
Now it makes sense why some implementations increase the auxiliary region to 32 bytes — to store longer small strings in the auxiliary region before switching into the regular mode with dynamically allocated buffer.
How big are small strings? Let’s see how many characters the auxiliary region can store. This is
what std::string().capacity() will tell us:
| C++ Standard Library | Small String Capacity |
|---|---|
| MSVC STL | 15 chars |
| GCC libstdc++ | 15 chars |
| LLVM libc++ | 22 chars |
Another surprise: LLVM with its 24 bytes for std::string fits more characters than MSVC or GCC
with their 32 bytes. (In fact, it’s possible to fully utilize the auxiliary region, so that n-byte
area fits n-1 chars and '\0'. Watch
CppCon 2016 talk for details.)
How fast are small strings? As with many things in programming, there is a tradeoff between memory utilization and code complexity. In other words, the more characters we want to squeeze into the auxiliary memory, the more complex logic we should invent. This results not only in more assembly operations, but also into branching that is not good for CPU pipelines.
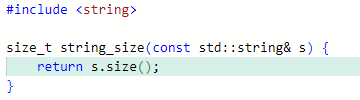
To illustrate this point, let’s see what the most commonly used size() method compiles to in
various standard libraries:
GCC stdlibc++. The function directly copies m_size field into the output register (see
https://godbolt.org/z/7nYe9rWdE):
| Example | GCC libstdc++ |
|---|---|
 |
 |
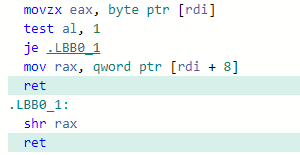
LLVM libc++. The function at first checks if the string is short and then calculates its size (see https://godbolt.org/z/xM349cG5P).
| Example | LLVM libc++ |
|---|---|
|
 |
LLVM code remains more complex for other methods too. It’s hard to say how badly this impacts the overall performance. The best advice is to keep this knowledge at hand and, for your particular use case, benchmark and experiment with various implementations.
Memory Allocation Policy
Finally, let’s come back to a long string mode and see how m_buffer grows when our string becomes
bigger. Some
comments
in the GCC source code, refer to the exponential growth policy. It’s not clear if this is an
internal GCC decision or part of the C++ Standard. In any case, all three implementations use
exponential growth, so that MSVC has 1.5x factor growth, while GCC and LLVM use 2x
factor.
The code below illustrates the growth algorithm in each implementation. The capacity examples show how the capacity changes as the string grows one character at a time in a loop:
-
MSVC STL
1size_t newCapacity(size_t newSize, size_t oldCap) { 2 return max(newSize, oldCap + oldCap / 2); 3}Capacity growth: 15, 31, 47, 70, 105, 157, 235, 352, 528, 792, 1'188, 1'782.
-
GCC libstdc++
1size_t newCapacity(size_t newSize, size_t oldCap) { 2 return max(newSize + 1, 2 * oldCap); 3}Capacity growth: 15, 30, 60, 120, 240, 480, 960, 1'920, 3'840, 7'680, 15'360.
-
LLVM libc++
1size_t newCapacity(size_t newSize, size_t oldCap) { 2 return max(newSize, 2 * oldCap) + 1; 3}Capacity growth: 22, 47, 95, 191, 383, 767, 1'535, 3'071, 6'143, 12'287.
Tha Last Word
The actual implementation of std::string varies among the most popular implementations of the C++
Standard Library. The main difference is in the Small String Optimization, which the C++ Standard
doesn’t define explicitly.
The following table summarizes some key facts about std::string:
| C++ Standard Library | String Size | Small String Capacity | Growth Factor |
|---|---|---|---|
| MSVC STL | 32 bytes | 15 chars | 1.5x |
| GCC libstdc++ | 32 bytes | 15 chars | 2x |
| LLVM libc++ | 24 bytes | 22 chars | 2x |
These details will be useful for every professional C++ developer. They are especially important when optimizing for CPU and memory efficiency.
For sure, I’m not the only one curious about how strings are implemented in other languages. What is different from C++, what is similar? Please, share your knowledge in the comments, I’d love to hear from you.
Thanks for reading TastyCode.
Recommended Links:
- The strange details of std::string at Facebook, CppCon 2016 talk by Nicholas Ormrod.
- libc++’s implementation of std::string by Joel Laity with the discussion on HN.
TastyCode by Oleksandr Gituliar.